How to Use GraphQL
What is GraphQL?
GraphQL is a query language for APIs that allows clients to request only the data they need. GraphQL APIs offer several benefits over REST APIs:
- Reduced data transfer: Specify the exact data you need
- Simplified client code: Simplify and easily maintain code without relying on multiple endpoints or parsing logic
- Powerful querying: Use nested queries, filtering, sorting, and pagination to find the data you need
Fluz uses a GraphQL API to provide a flexible, modern, and secure integration experience. This guide is for those new to GraphQL and provides an overview of how GraphQL works to help prepare you to use Fluz’s API.
How it Works
At its core, GraphQL operates on a defined type system called a schema. The schema describes the types of data available. Unlike REST APIs, where each endpoint typically corresponds to a specific resource and returns fixed datasets, GraphQL has a single endpoint that allows clients to specify the data they need using queries. Fetching data from a single endpoint allows clients to use single requests with specific fields to get all the data they need, reducing over-fetching and under-fetching data.
When a client sends a query, the server checks it against a schema defining the available data types. Then, it uses resolver functions to gather the requested data from different sources. These functions work simultaneously, making data retrieval efficient. Finally, the server returns the collected data to the client in a single JSON object.
Key Concepts
The following sections break down GraphQL's key concepts to help you understand how a GraphQL API works and how to interact with it.
Operations
GraphQL uses the term operations to define request types. The following three operations are used in GraphQL for sending requests:
- Query: Used to fetch data
- Mutation: Used to write data
- Subscription: Use to write data in real-time
The Fluz API does not currently use subscriptions.
Type System
GraphQL uses a type system called a schema to describe what data can be queried. The building blocks of a schema are object types. Objects represent data you can fetch, with each object having fields. These fields are the specific pieces of data you can request.
Arguments
Every field on a GraphQL object can have zero or more arguments. Arguments work like filters for additional information to help refine the data you request.
An argument can be required or optional. If required, it is indicated with a "!" on the argument type.
Ex: giftCardId: UUID!
Queries and Mutations
Queries and mutations are special objects that define the entry point of a GraphQL query. As noted in this guide, queries and mutations are operations that fetch or write data.
The Query type is a special type that defines the entry point of every GraphQL query. Queries are used to request and retrieve data. Unlike REST, GraphQL queries define what fields will be included in their response. In the Fluz API, data is most often retrieved using the node query, which can fetch any type by its globally unique id.
The Mutation type is a special type that is used to write or modify data. A mutation’s response reflects the data after it has been updated. While query fields are executed in parallel, mutation fields run in series. This ensures each operation completes before the next begins.
Refer to the following pages of Fluz API Reference for available queries and mutations:
Objects
Objects are a fundamental component of GraphQL schemas. They organize data you can request and receive from a service into types. They contain a collection of fields, each of which has its own type.
For a complete list of the Fluz API’s objects, see Objects in the API Reference.
Scalars
A Scalar type is a primitive provided by GraphQL. All fields ultimately resolve to a scalar. A GraphQL object type has a name and fields, but those fields have to resolve to produce concrete data. This is where scalar types come in.
For a complete list of the Fluz API’s scalars, see Scalars in the API Reference.
Enums
Enumeration types, also called enums, are a special kind of scalar restricted to a specific set of values. Enums allow you to:
- Validate that any arguments of this type are one of the allowed fields
- Facilitate communication through the schema that a field will always be one of a finite set of values
For a complete list of the Fluz API’s enums, see Enums in the API Reference.
Interfaces
Interfaces define a set of fields that other types must include to be considered that type. Interfaces are useful when you want to return an object or set of objects of several different types. This allows you to query for objects of other specific types as long as they share those required fields defined in the interface.
Learn more about the GraphQL Interfaces and Unions here.
Unions
Union types are another way to define possible return types for a field. Unlike interfaces, they don’t have shared fields. When you query a field that uses a union type, you must use a special fragment to specify which fields you want depending on the returned type.
Learn more about the GraphQL Interfaces and Unions here.
Fragments
Fragments allow you to share fields between operations. A GraphQL fragment is a set of fields you can reuse across multiple queries and mutations. Fragments are especially useful when colocated with components to define the component's data requirements.
Learn more about the GraphQL Fragments here.
Using Fragments with Unions and Interfaces
You can define fragments on unions and interfaces using in-line fragments. Using the ... on key phrase, you will be able to query between different object types conditionally. Use the __typename reserved field if you would like to see which type is being conditionally returned.
Learn more about the GraphQL Using Fragments with Unions and Interfaces here.
Inputs Objects
The input type is a special object type that groups a set of arguments together. This is particularly valuable in the case of mutations, where you might want to pass in a whole object to be created. In the Fluz API we also use inputs for filtering in queries. Input types define the structure of the data you’re sending. Input types are valuable for mutations where you want to pass in a whole object.
For a complete list of the Fluz API’s inputs, see Input Objects in the API Reference.
Introspection
Fluz’s API has an introspection system that allows authenticated users to fully introspect the API. We recommend using the Fluz API Explorer to test the API’s introspection system in the test environment.
You can paste the following code sample into the Query section of the API Explorer to try out introspection:
{
__schema {
types {
name
}
}
}Node Queries and Global IDs
The Fluz API uses node queries and global IDs to look up individual objects. A node query is defined as a pattern that allows clients to pass a global ID without specifying the entity it represents.
Pagination
When querying listed data, you can limit the number of records returned to allow for faster response times and smaller payloads. The Fluz API automatically paginates data following the Relay Cursor Connections Specification. This specification uses the edges field to obtain a list of items. Each item has the following:
A cursor that specifies its position in the list
A node that contains the requested fields
$first and $after variables to let the Fluz API know which records to return. You can adjust these variables to return as much or as little data as possible. Note the following when using these variables:
$first: An integer value used to specify the maximum number of items you want to fetch at once$after: A string value used to specify a cursor to indicate where in the list of items you want to start fetching data
By default, the Fluz API uses a value of 50 for the $first variable if the user does not define one.
Queries as a whole return a list of data that can also utilize pagination. Please refer to the OffsetInput:
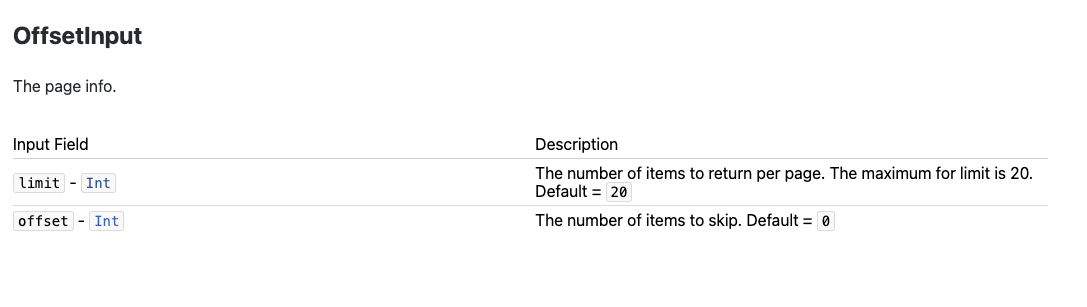
Example:
{
hero {
name
friends(first:2 after:$friendId) {
edges {
node {
name
}
cursor
}
}
}
}Making Requests
The Fluz API serves data as JSON over HTTP(s). GraphQL does not use HTTP verbs (GET, PUT, etc.) or have multiple endpoints per resource. Instead, you make POST requests to a single endpoint using specific queries or mutations.
Requests to the Fluz API should contain the following:
queryormutation: The operation of the request- Optional -
variables: A JSON payload used to pass dynamic data in a request - Optional -
operationName: Specifies an action in the case multiple queries are sent
You should use the application/json content type, and include a JSON-encoded body of the following form:
{
"query": "...",
"operationName": "...",
"variables": { "myVariable": "someValue", ... }
}Response
Regardless of the method by which the query and variables were sent, the response should be returned in the body of the request in JSON format. As mentioned in the spec, a query might result in some data and some errors, and those should be returned in a JSON object of the form:
{
"data": { ... },
"errors": [ ... ]
}
Clients and Codegen
The GraphQL ecosystem is dynamic and strongly enhances developers' and integrators' experiences. As a result, GraphQL supports innovation and modern approaches to development. When using the Fluz API, we recommend the following desktop clients, extensions, and codegens.
Desktop Clients
When developing with GraphQL APIs, using a GUI tool that leverages introspection to provide documentation and type hints is helpful. Some of the tools we recommend using include:
Editor Plugins and Browser Extensions
We recommend the following plugins for various IDEs to make your development experience more seamless:
- GraphQL Developer Tools (Chrome)
- Altair (Chrome, Firefox)
- GraphQL DevTools (Firefox)
- VSCode GraphQL
- vim-graphql
- JS GraphQL (IntelliJ, WebStorm)
Codegen Tools
We recommend using GraphQL Code Generator to generate TypeScript definitions and SDKs for use with GraphQL.
Updated about 1 year ago